library(tidyverse)
theme_set(theme_light())
pima <- as_tibble(MASS::Pima.tr)
pima <- pima |>
mutate(pregnancy = ifelse(npreg > 0, "Yes", "No")) # whether the patient has had any pregnanciesSupervised learning: logistic regression
Why not linear regression for categorical data?
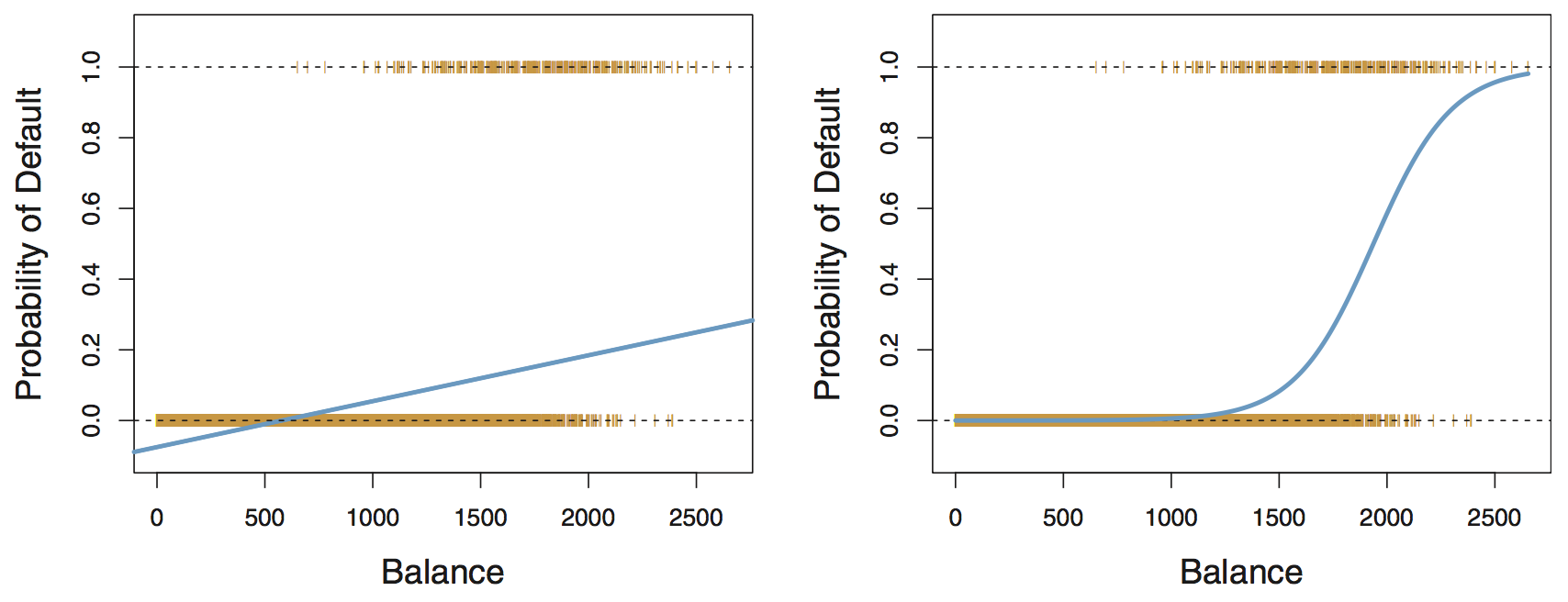
Linear regression: predicted probabilities might be outside the \([0, 1]\) interval
Logistic regression: ensures all probabilities lie between 0 and 1
View predicted probability relationship
pima |>
mutate(pred_prob = fitted(pima_logit),
i_type = as.numeric(type == "Yes")) |>
ggplot(aes(bp)) +
geom_line(aes(y = pred_prob, color = pregnancy), linewidth = 2) +
geom_point(aes(y = i_type), alpha = 0.3, color = "darkorange", size = 4)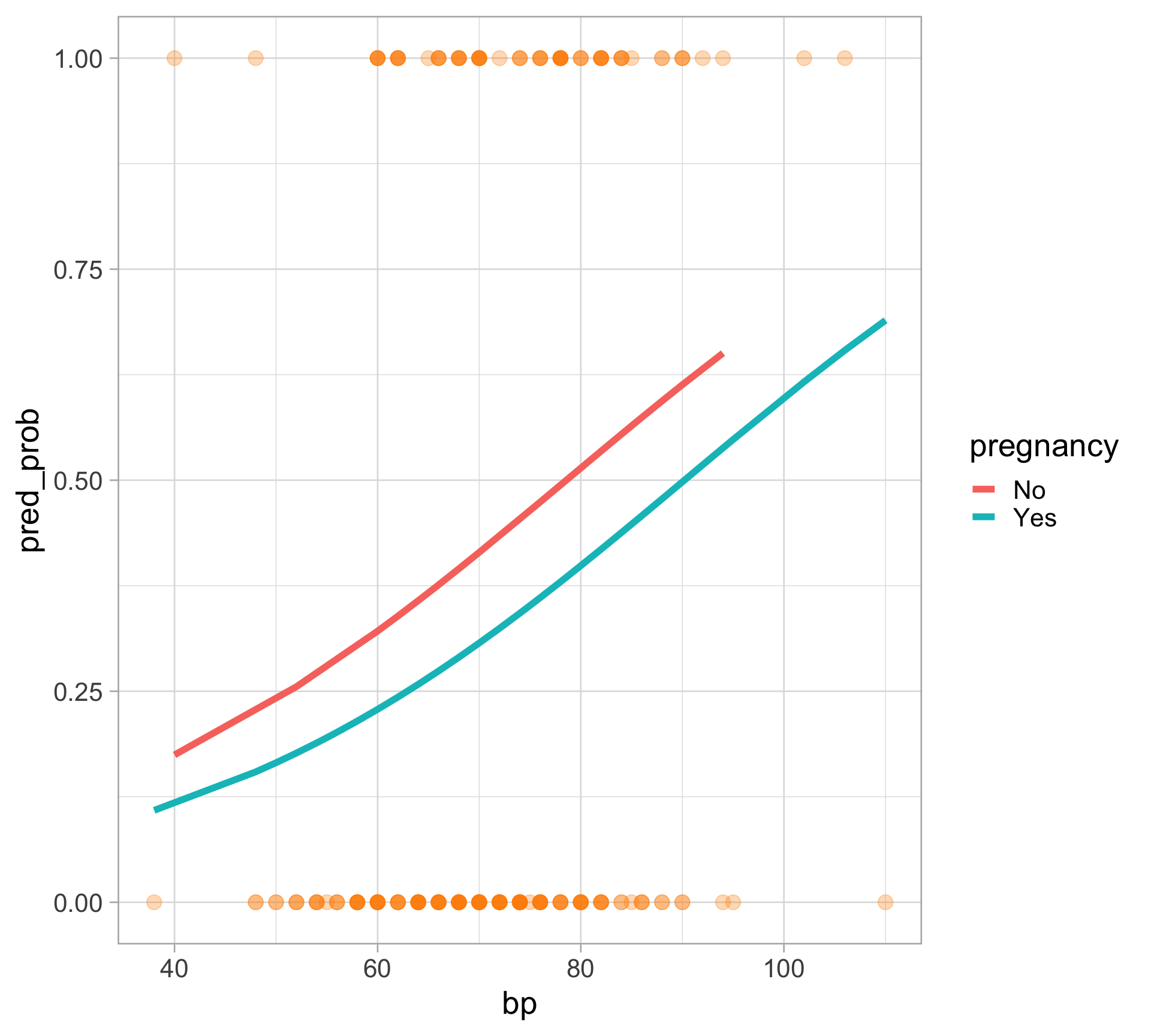
Confusion matrix
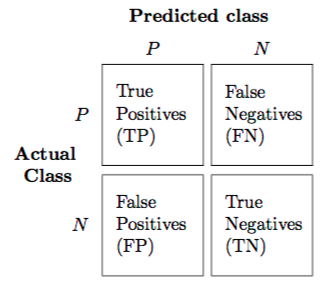
Accuracy: How often is the classifier correct? \((\text{TP} + \text{TN}) \ / \ {\text{total}}\)
Precision: How often is it right for predicted positives? \(\text{TP} \ / \ (\text{TP} + \text{FP})\)
Sensitivity (or true positive rate (TPR) or power): How often does it detect positives? \(\text{TP} \ / \ (\text{TP} + \text{FN})\)
Specificity (or true negative rate (TNR), or 1 - false positive rate (FPR)): How often does it detect negatives? \(\text{TN} \ / \ (\text{TN} + \text{FP})\)
Receiver operating characteristic (ROC) curve
- Want to maximize the area under the curve (AUC)
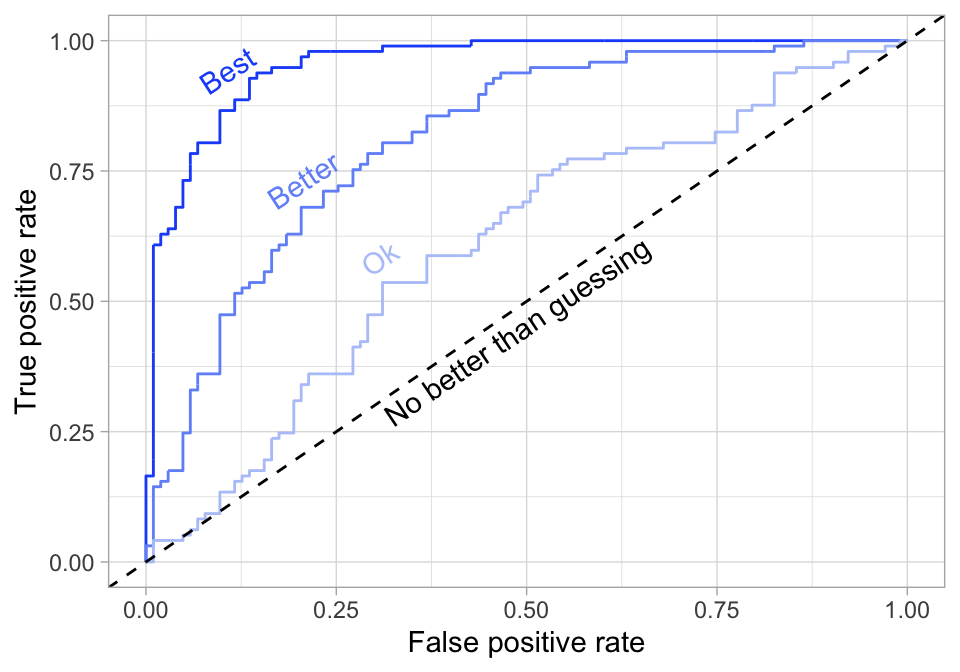
Calculating AUC & plotting an ROC curve
library(pROC)
pima_roc <- pima |>
mutate(pred_prob = predict(pima_logit,
type = "response")) |>
roc(type, pred_prob)
# str(pima_roc)
pima_roc$aucArea under the curve: 0.6428tibble(threshold = pima_roc$thresholds,
specificity = pima_roc$specificities,
sensitivity = pima_roc$sensitivities) |>
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path() +
geom_abline(slope = 1, intercept = 0,
linetype = "dashed")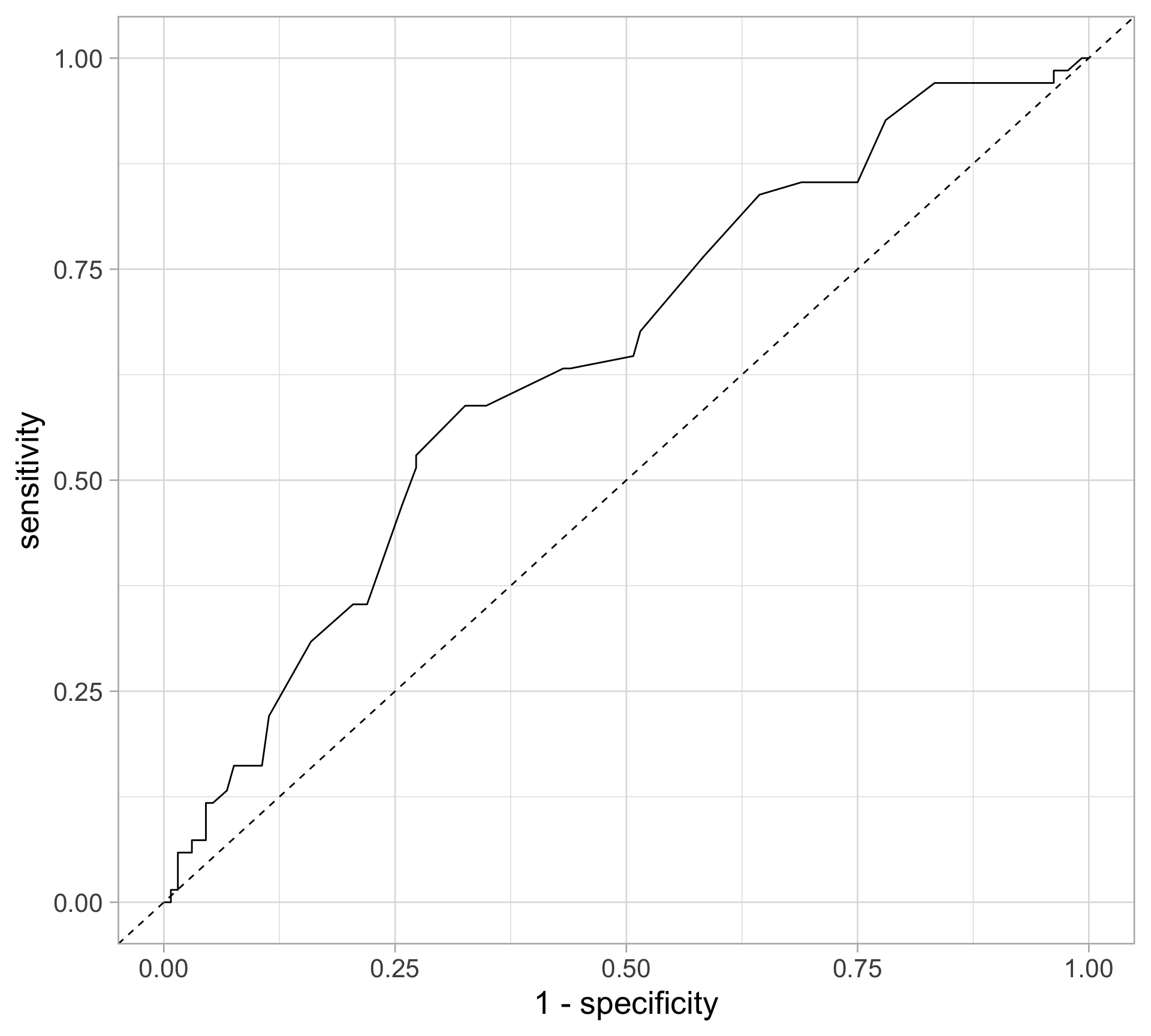
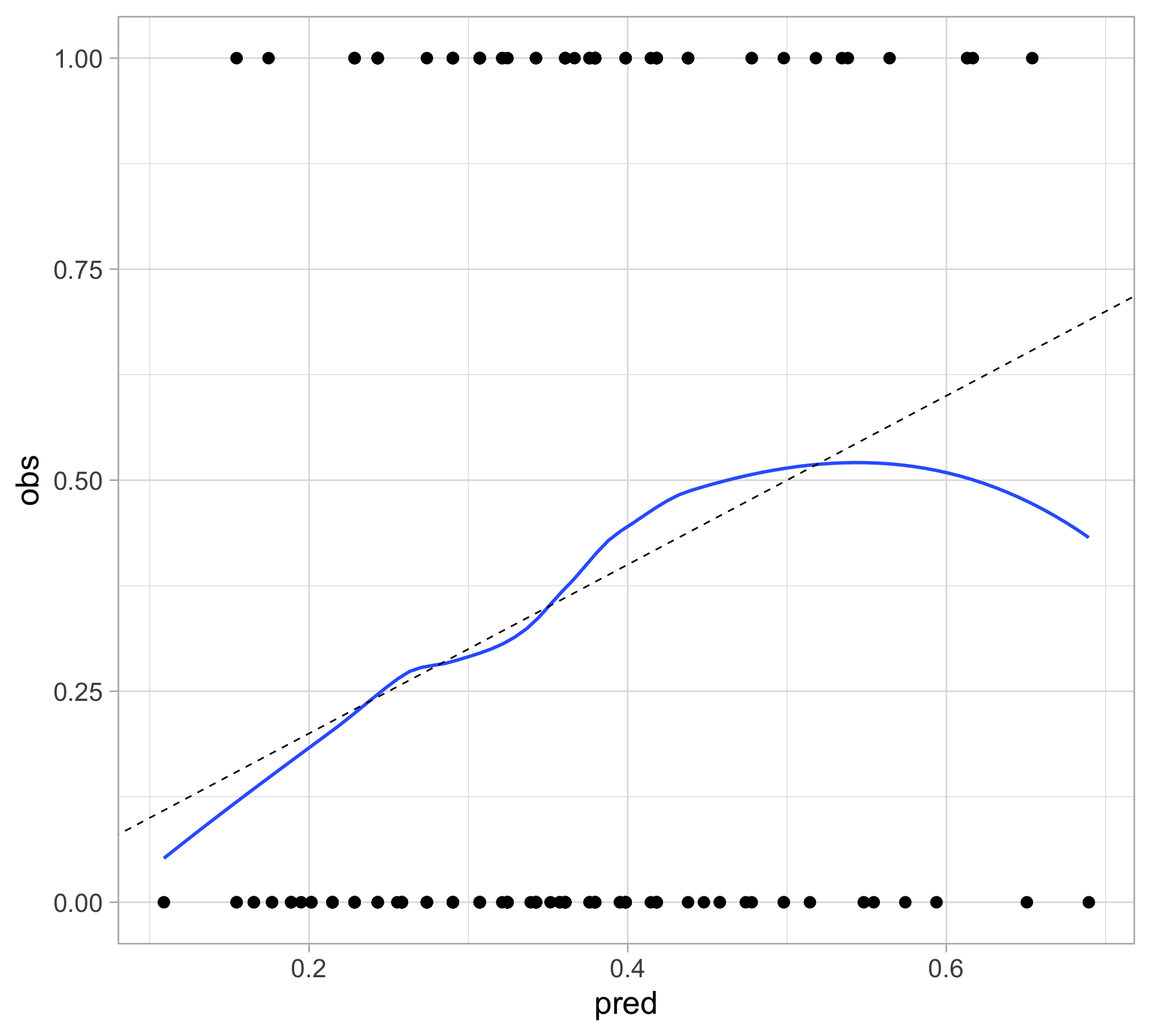
Calibration plot: smoothing
Plot the observed outcome against the fitted probability, and apply a smoother
pima |>
mutate(pred = predict(pima_logit, type = "response"),
obs = ifelse(type == "Yes", 1, 0)) |>
ggplot(aes(pred, obs)) +
geom_point() +
geom_smooth(se = FALSE) +
geom_abline(slope = 1, intercept = 0,
linetype = "dashed") Looks good for the most part
odd behavior for high probability values
since there are only a few observations with high predicted probability
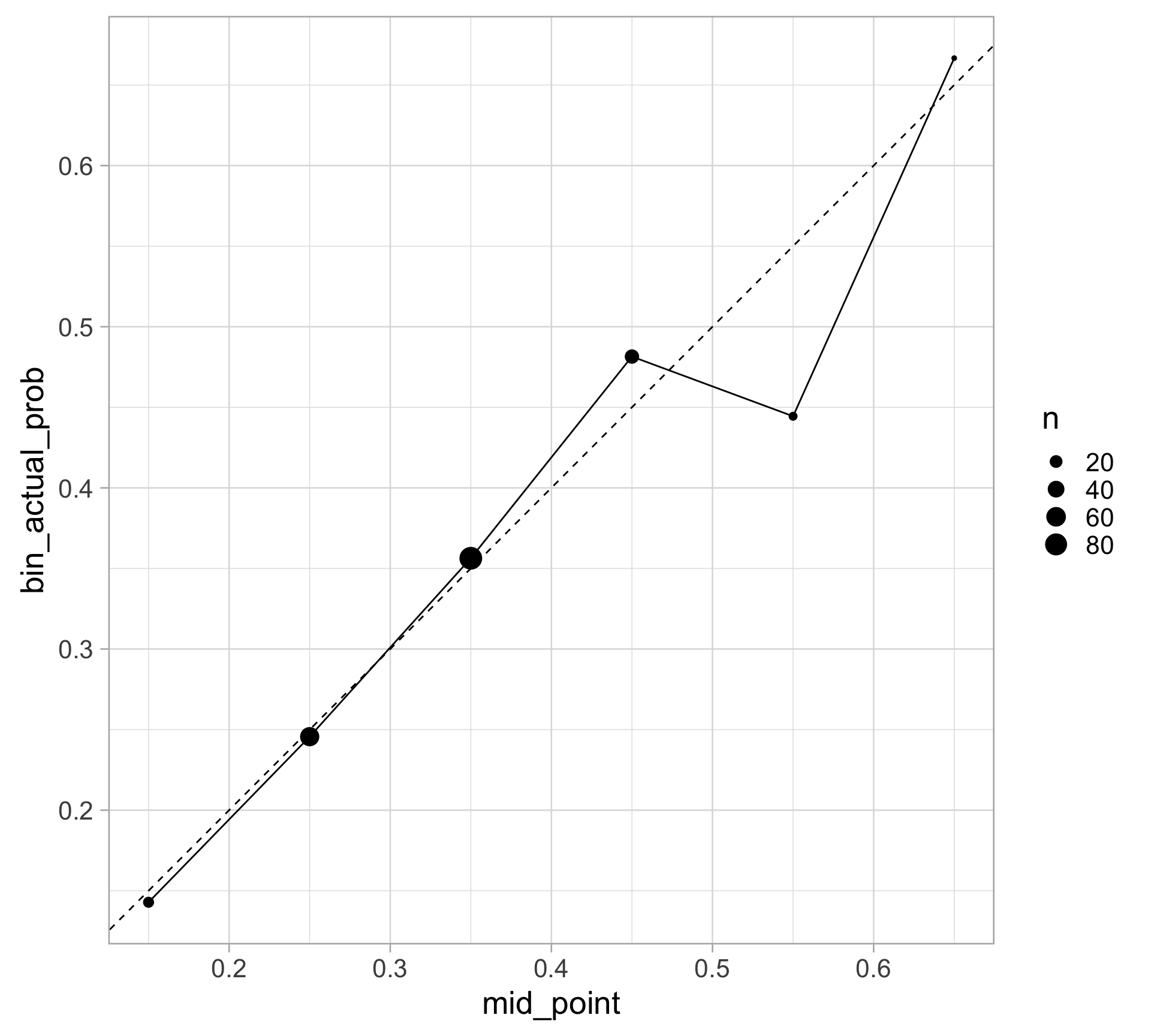
Calibration plot: binning
pima |>
mutate(
pred_prob = predict(pima_logit, type = "response"),
bin_pred_prob = cut(pred_prob, breaks = seq(0, 1, .1))
) |>
group_by(bin_pred_prob) |>
summarize(n = n(),
bin_actual_prob = mean(type == "Yes")) |>
mutate(mid_point = seq(0.15, 0.65, 0.1)) |>
ggplot(aes(x = mid_point, y = bin_actual_prob)) +
geom_point(aes(size = n)) +
geom_line() +
geom_abline(slope = 1, intercept = 0,
color = "black", linetype = "dashed") +
# expand_limits(x = c(0, 1), y = c(0, 1)) +
coord_fixed()