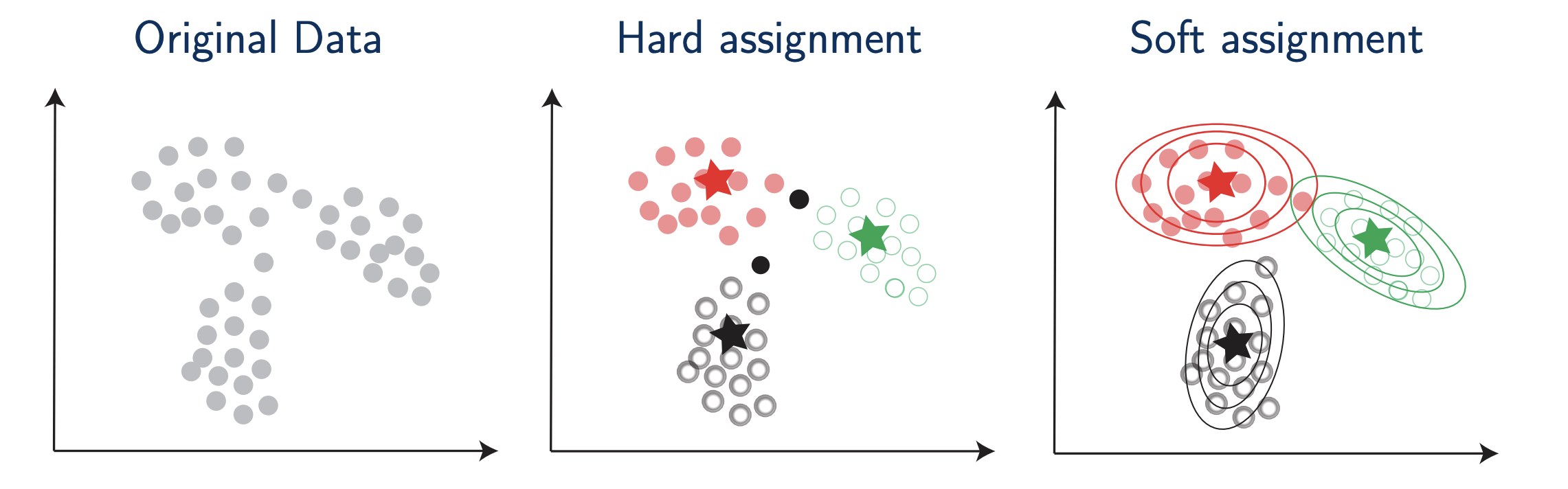
number of iterations= 29 Unsupervised learning: Gaussian mixture models
Motivating figure
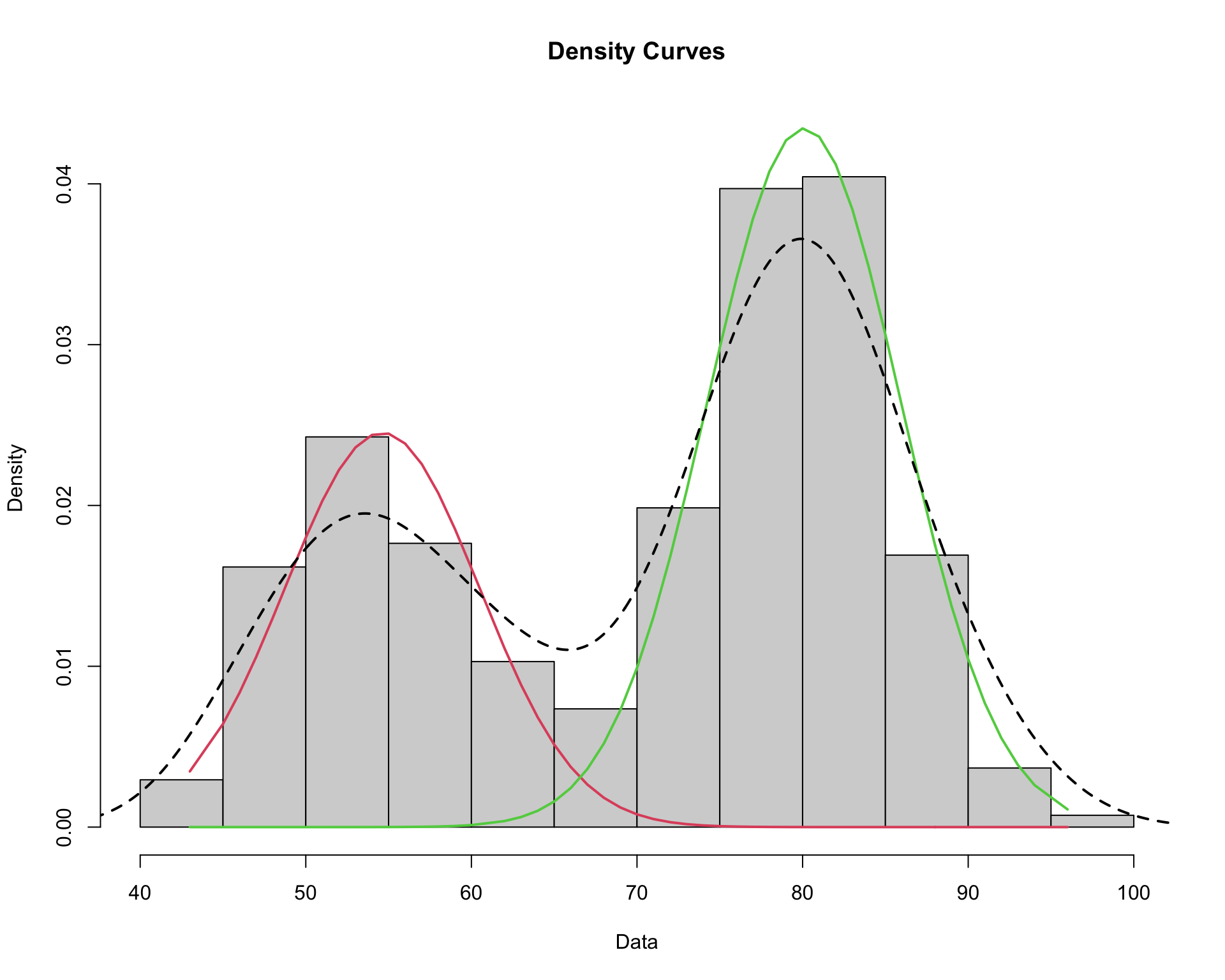
Mixtures of Gaussians in 1D
We would like to model the density of the data points, but due to the apparent multi-modality, a single Gaussian distribution would not be appropriate
There seems to be two separate underlying regimes, so instead we model the density as a mixture of Gaussians
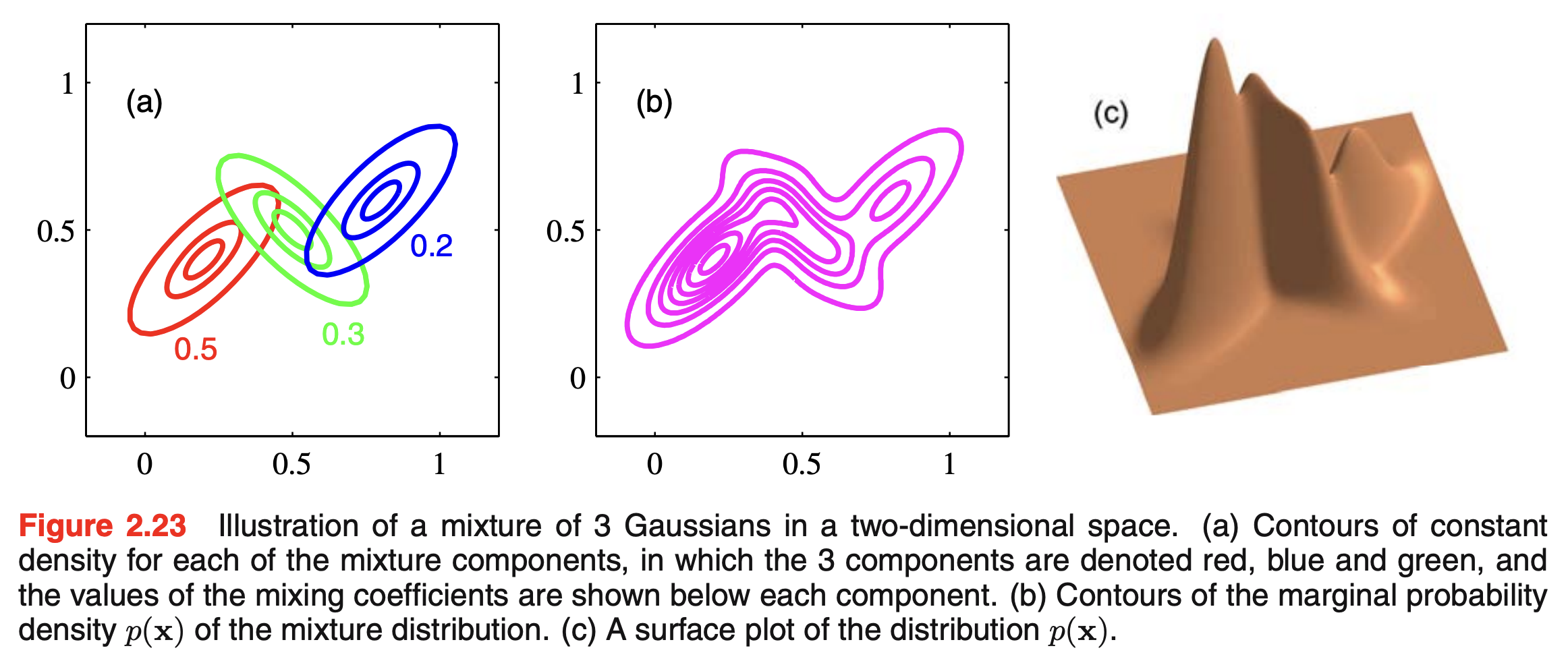
Mixtures of Gaussians in 2D
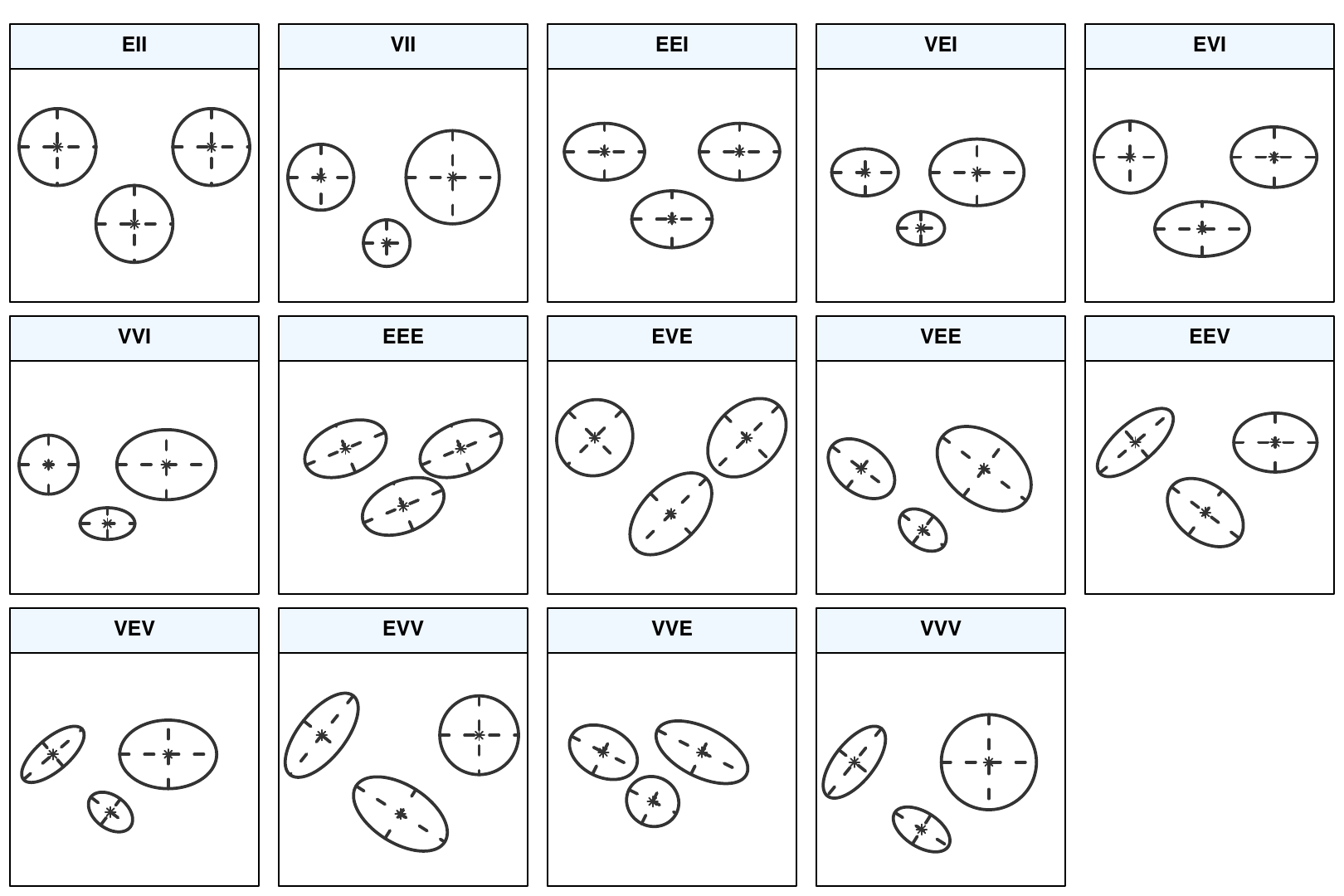
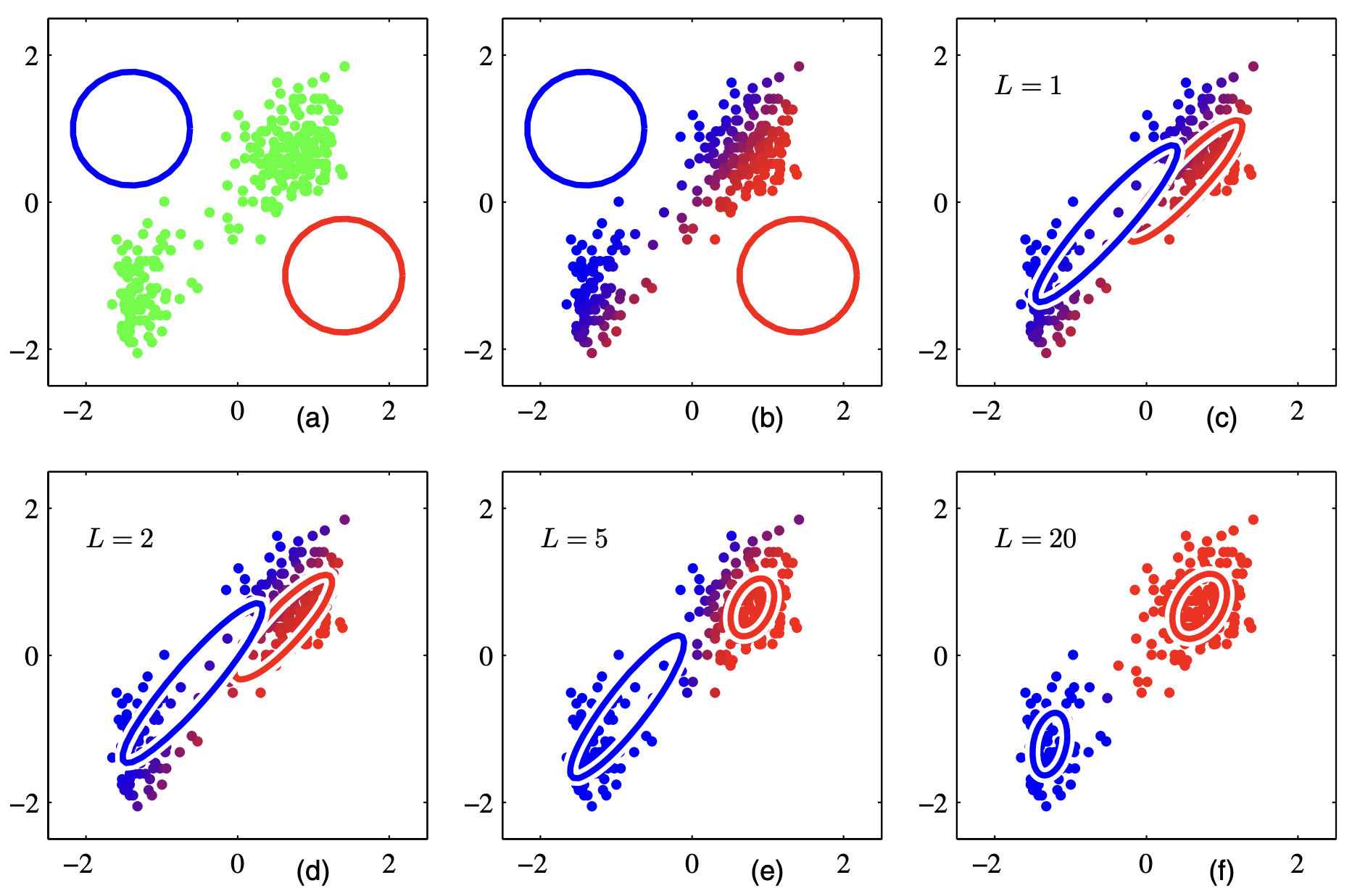
Covariance constraints
3 letters in model name denote (in order) the volume, shape, and orientation across clusters
EM algorithm example
View clustering assignments
nba_mclust |>
augment() |>
ggplot(aes(x = x3pa, y = trb, color = .class, size = .uncertainty)) +
geom_point(alpha = 0.6) +
ggthemes::scale_color_colorblind()
Display the BIC for each model and number of clusters
nba_mclust |>
plot(what = "BIC",
legendArgs = list(x = "bottomright", ncol = 4))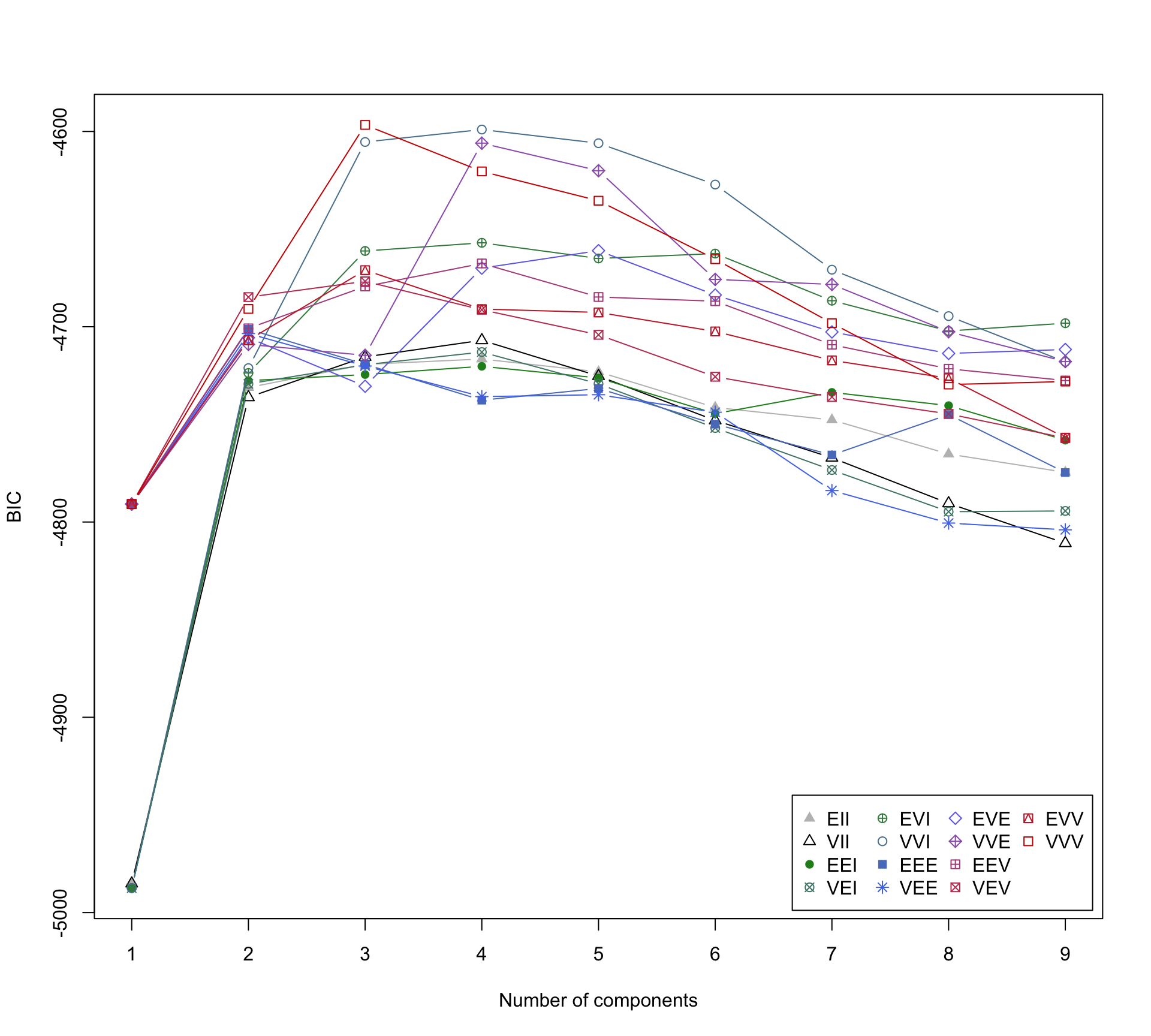
nba_mclust |>
plot(what = "classification")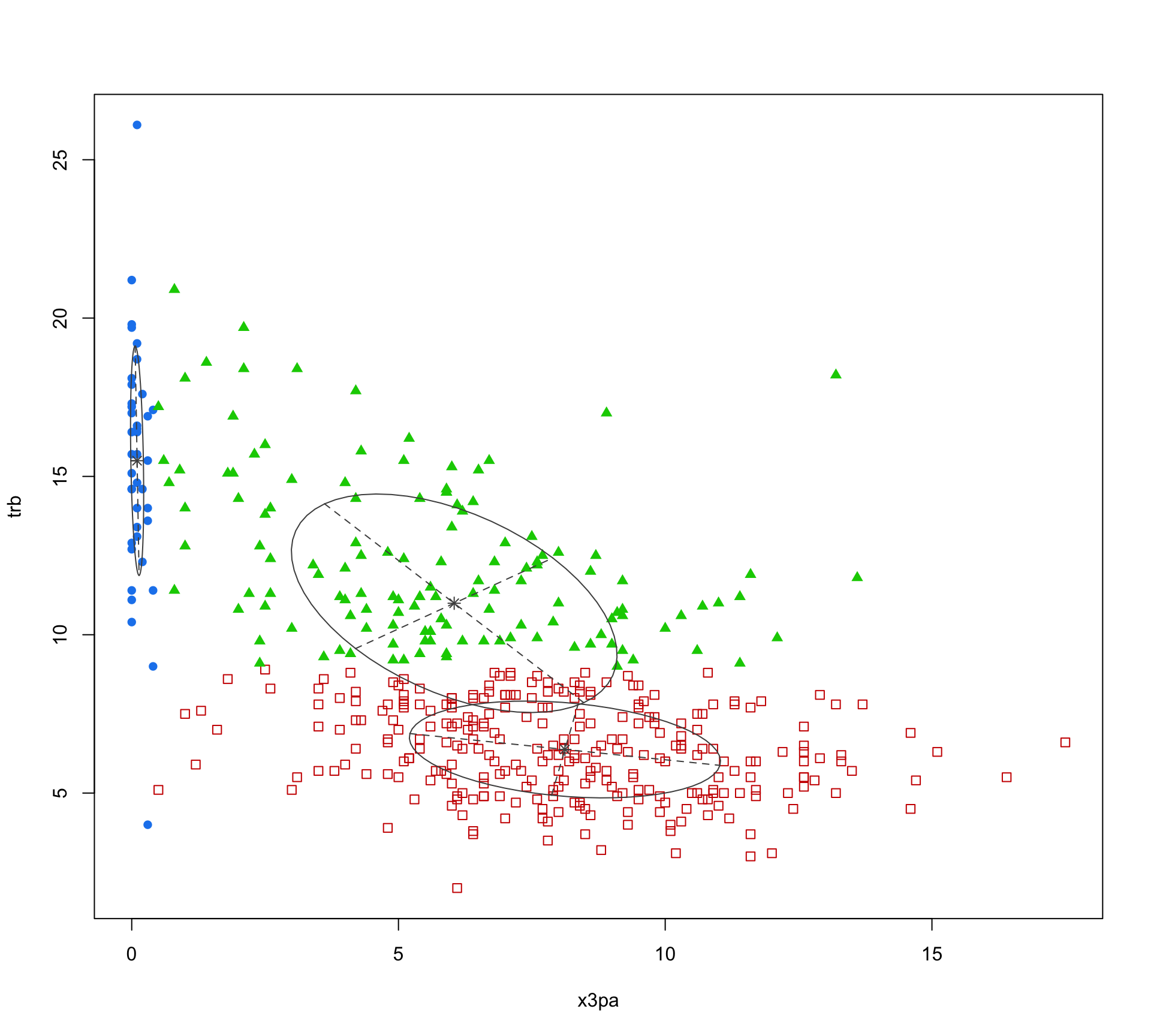
What about the cluster probabilities?
nba_player_probs <- nba_mclust$z
colnames(nba_player_probs) <- str_c("cluster", 1:3)
nba_player_probs <- nba_player_probs |>
as_tibble() |>
mutate(player = nba_players$player) |>
pivot_longer(!player, names_to = "cluster", values_to = "prob")
nba_player_probs |>
ggplot(aes(prob)) +
geom_histogram() +
facet_wrap(~ cluster)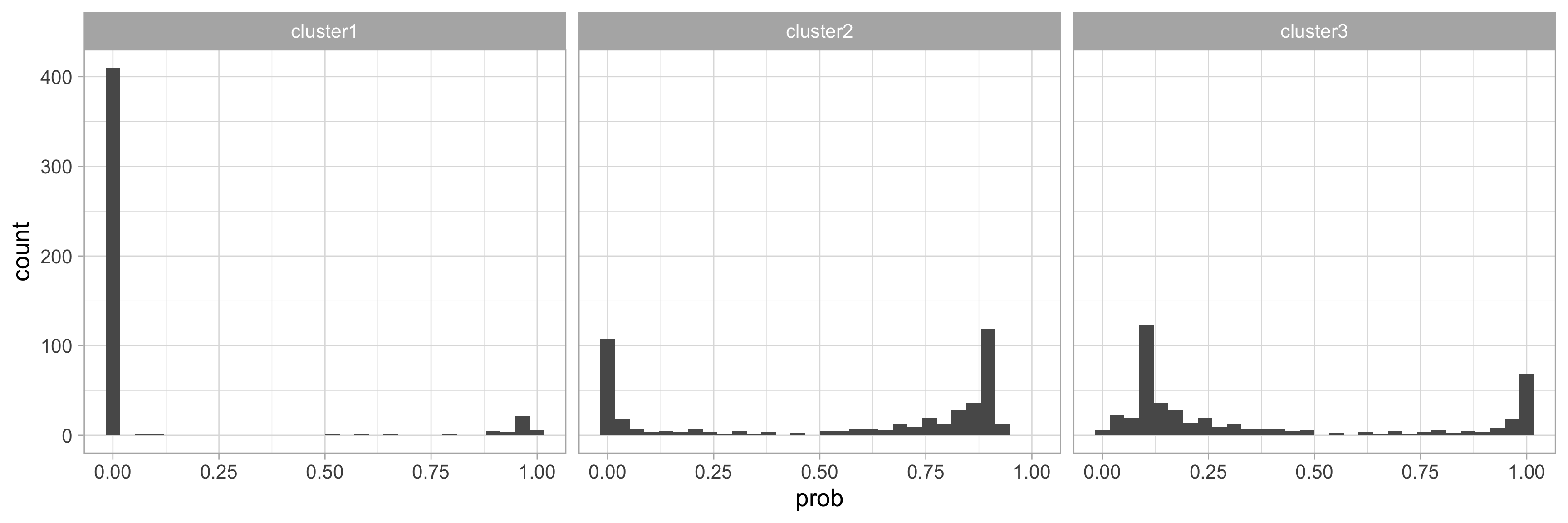
Which players have the highest uncertainty?
nba_players |>
mutate(cluster = nba_mclust$classification,
uncertainty = nba_mclust$uncertainty) |>
group_by(cluster) |>
slice_max(uncertainty, n = 5) |>
mutate(player = fct_reorder(player, uncertainty)) |>
ggplot(aes(x = uncertainty, y = player)) +
geom_point(size = 3) +
facet_wrap(~ cluster, scales = "free_y", nrow = 3)