Supervised learning: nonparametric regression
Why use smooth functions rather that just coefficients?
- Relationships between individual predictors and the response are smooth
- Estimate the smooth relationships simultaneously to predict the response by adding them up

- GAMs have the advantage over GLMs of greater flexibility (want to model the covariates flexibly, covariates and response not necessarily linearly related)
A disadvantage of GAMs/smoothing methods is the loss of interpretability
How do we interpret the effect of a predictor on the response?
How do we perform inferences for those effects?
Generalized additive models (GAMs)

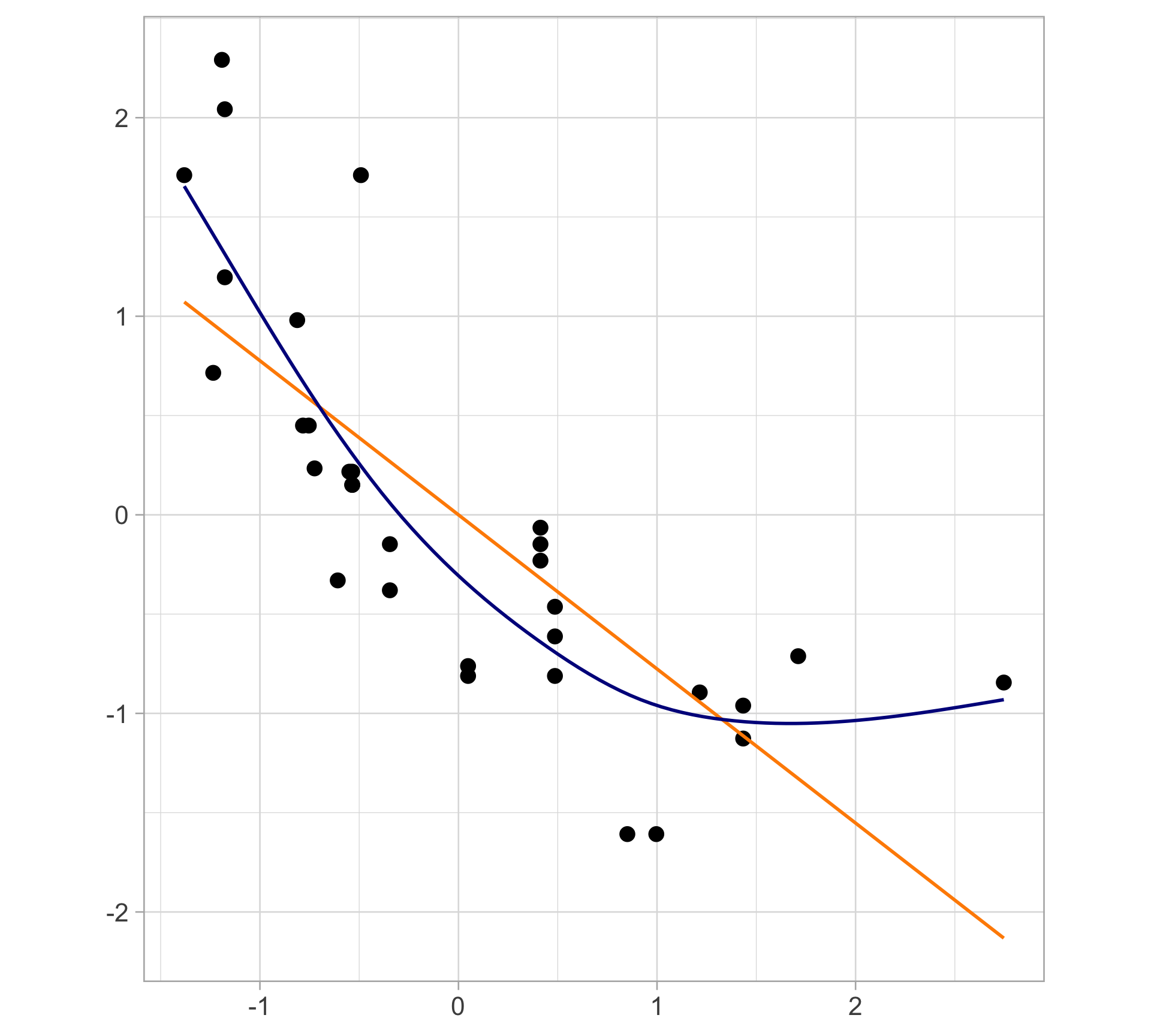
Toy example: is this linear?
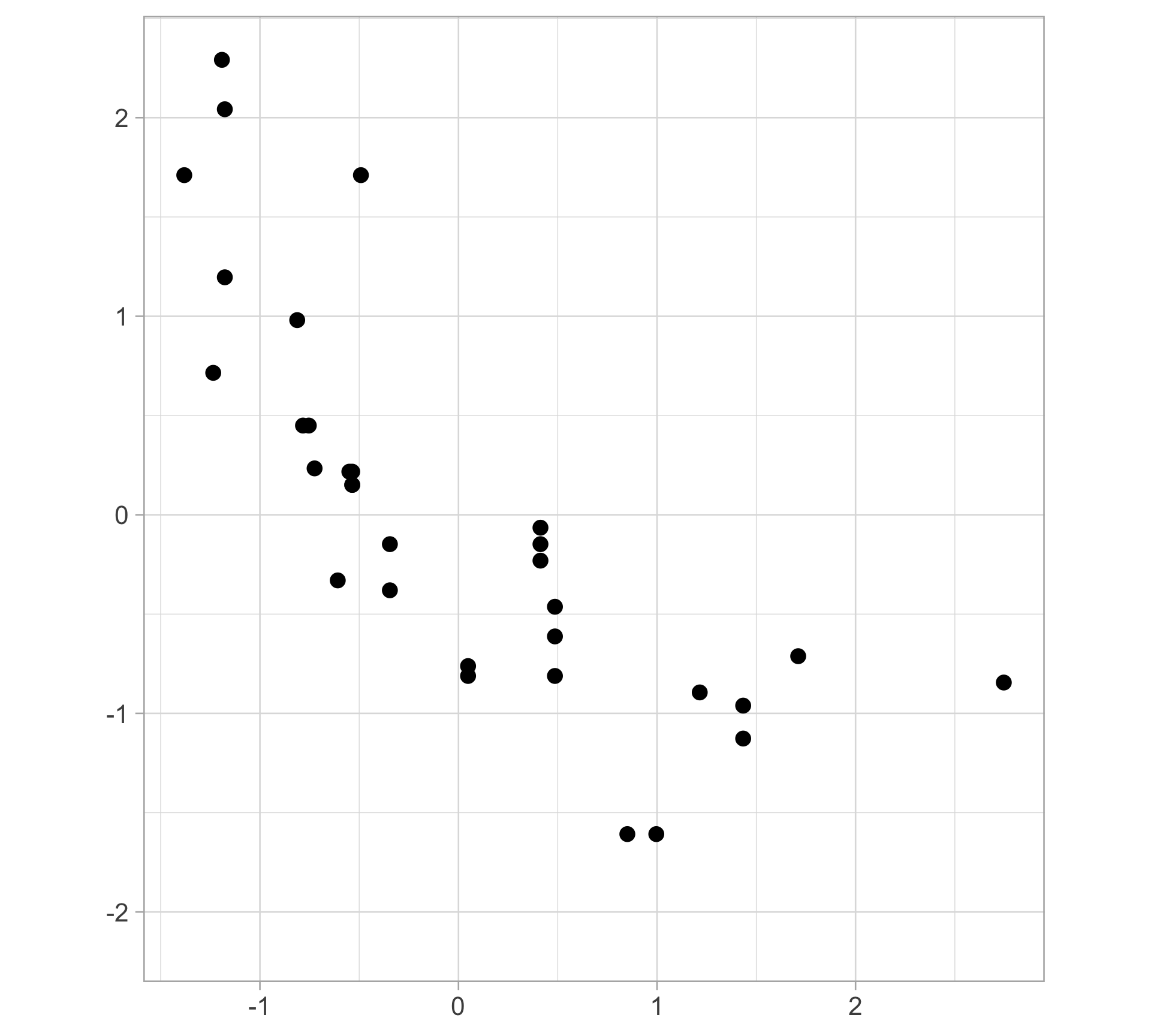
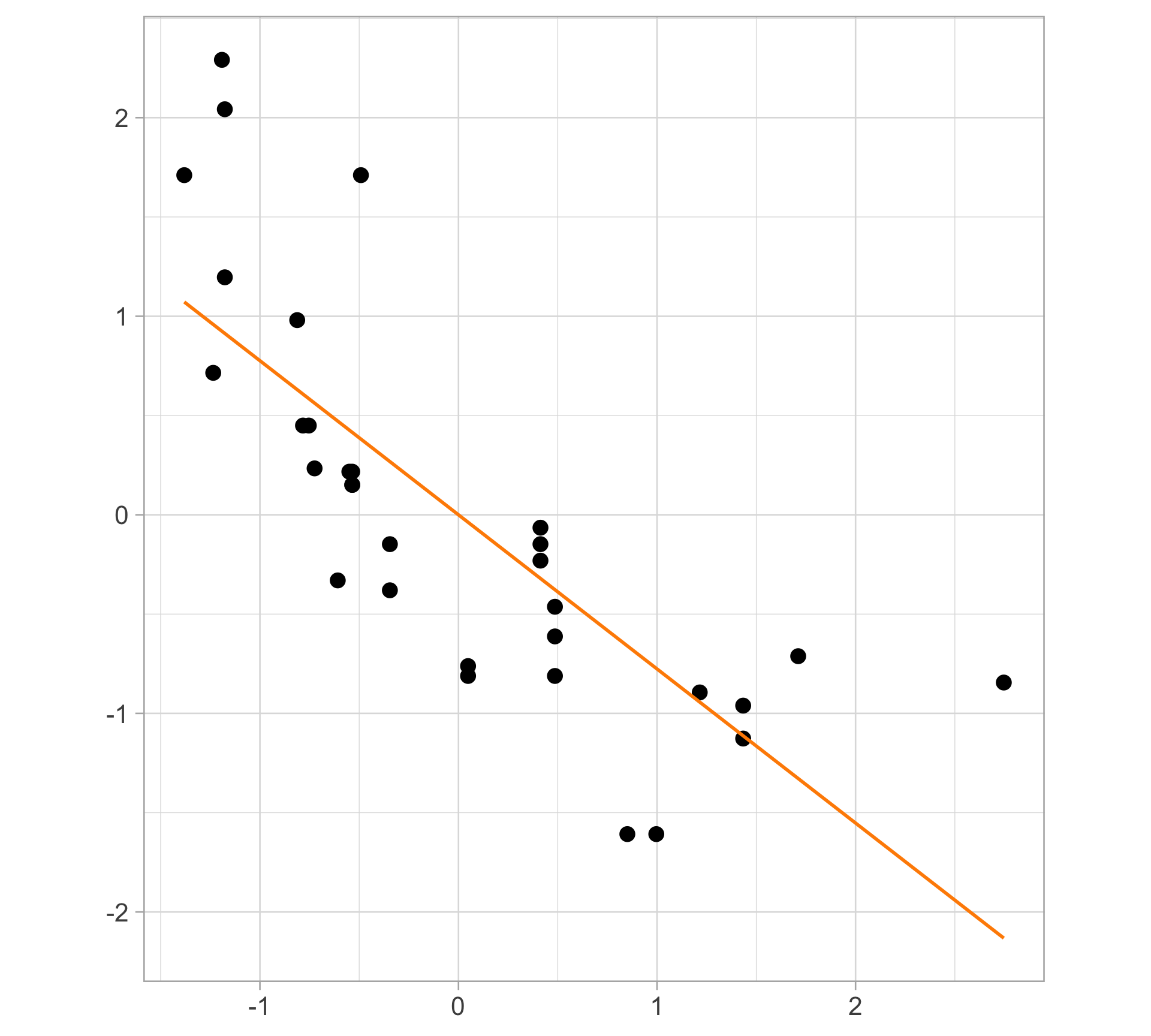
Toy example: linear regression fit
Toy example: GAM fit
Weight basis functions to obtain spline
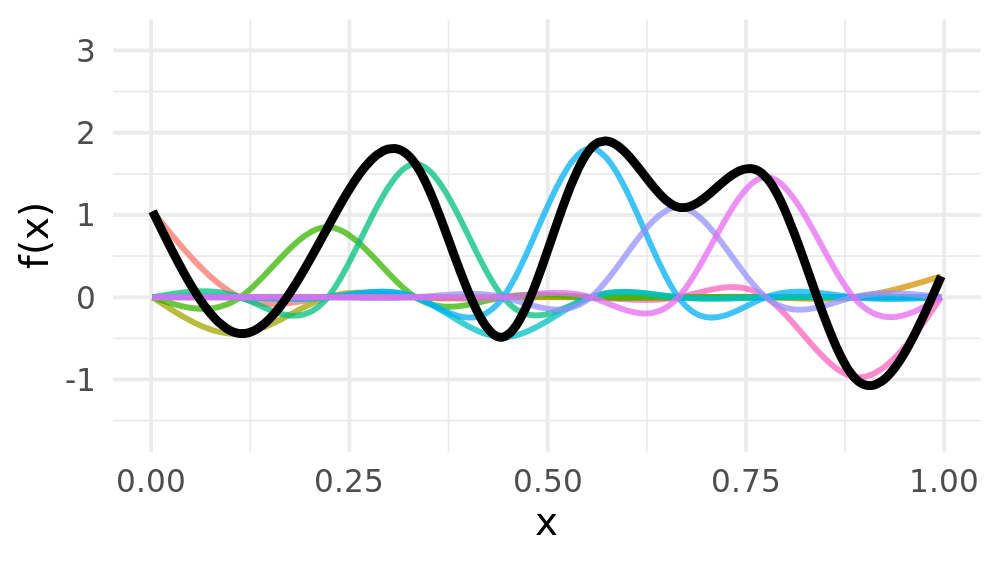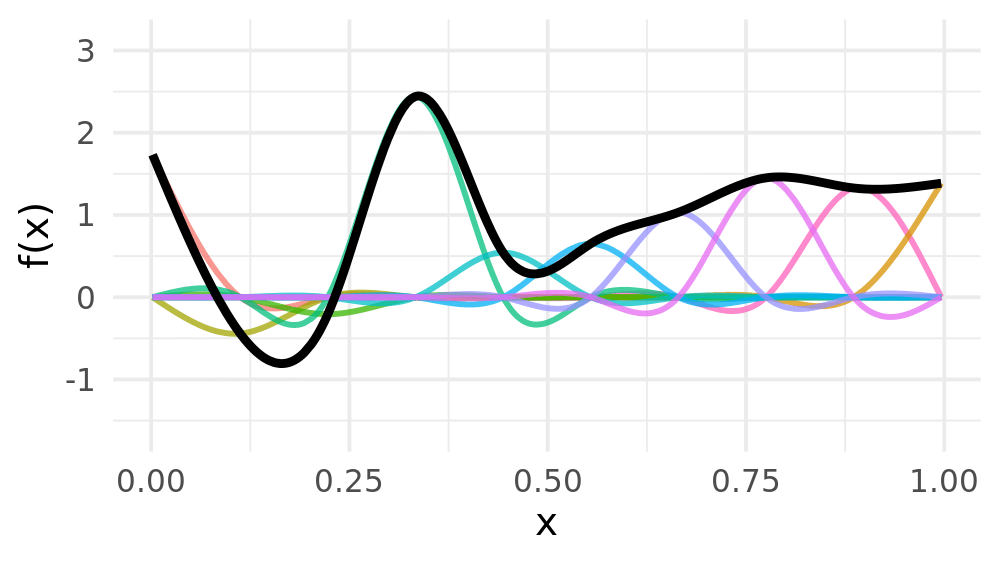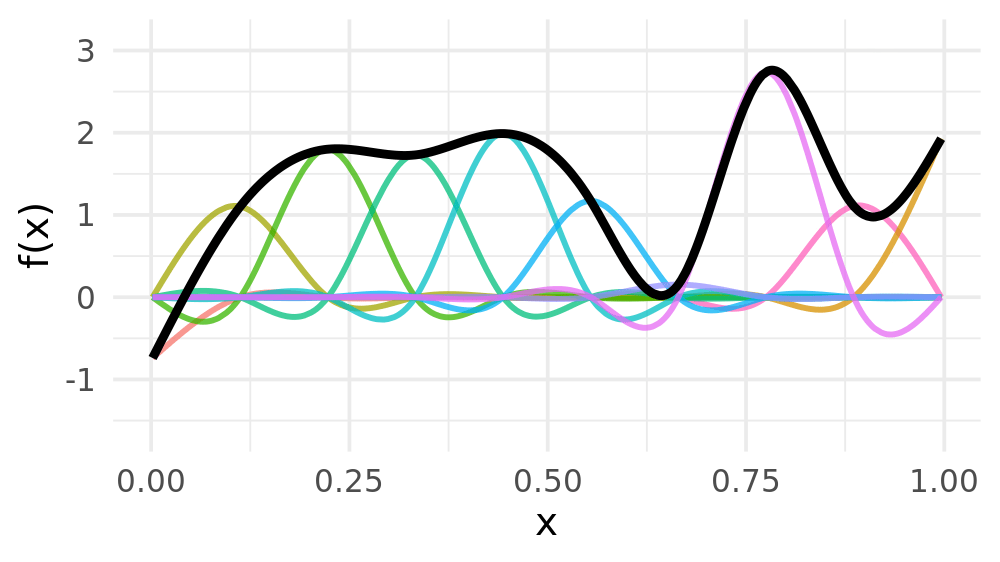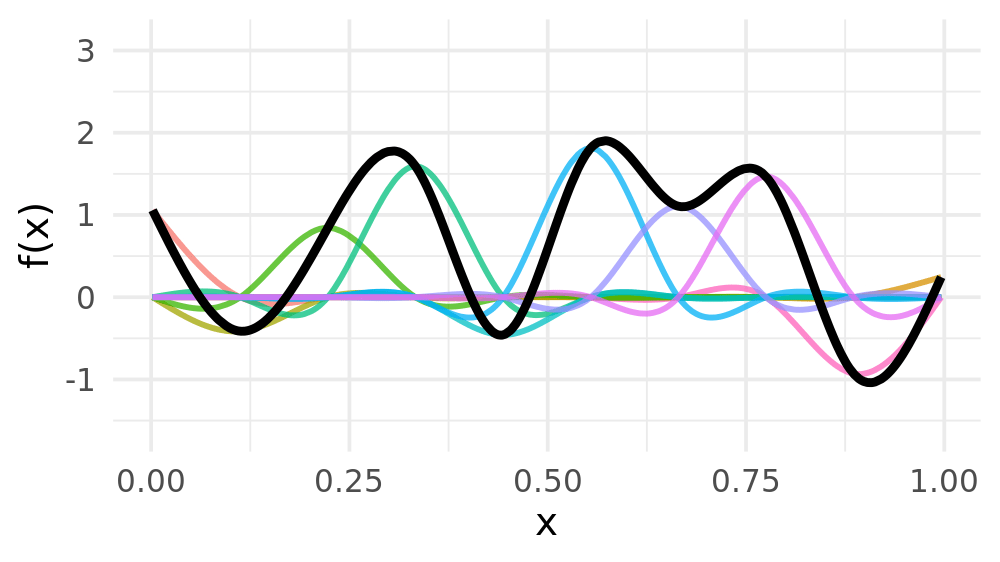
Smoothing splines
Goal: Estimate the smoothing spline \(\hat{s}(x)\) that balances the tradeoff between the model fit and wiggliness
Remember: Goldilocks principle

Predicting HRs with launch angle and exit velocity
HRs are relatively rare and confined to one area of this plot
batted_balls |>
ggplot(aes(x = launch_speed,
y = launch_angle,
color = as.factor(is_hr))) +
geom_point(alpha = 0.2)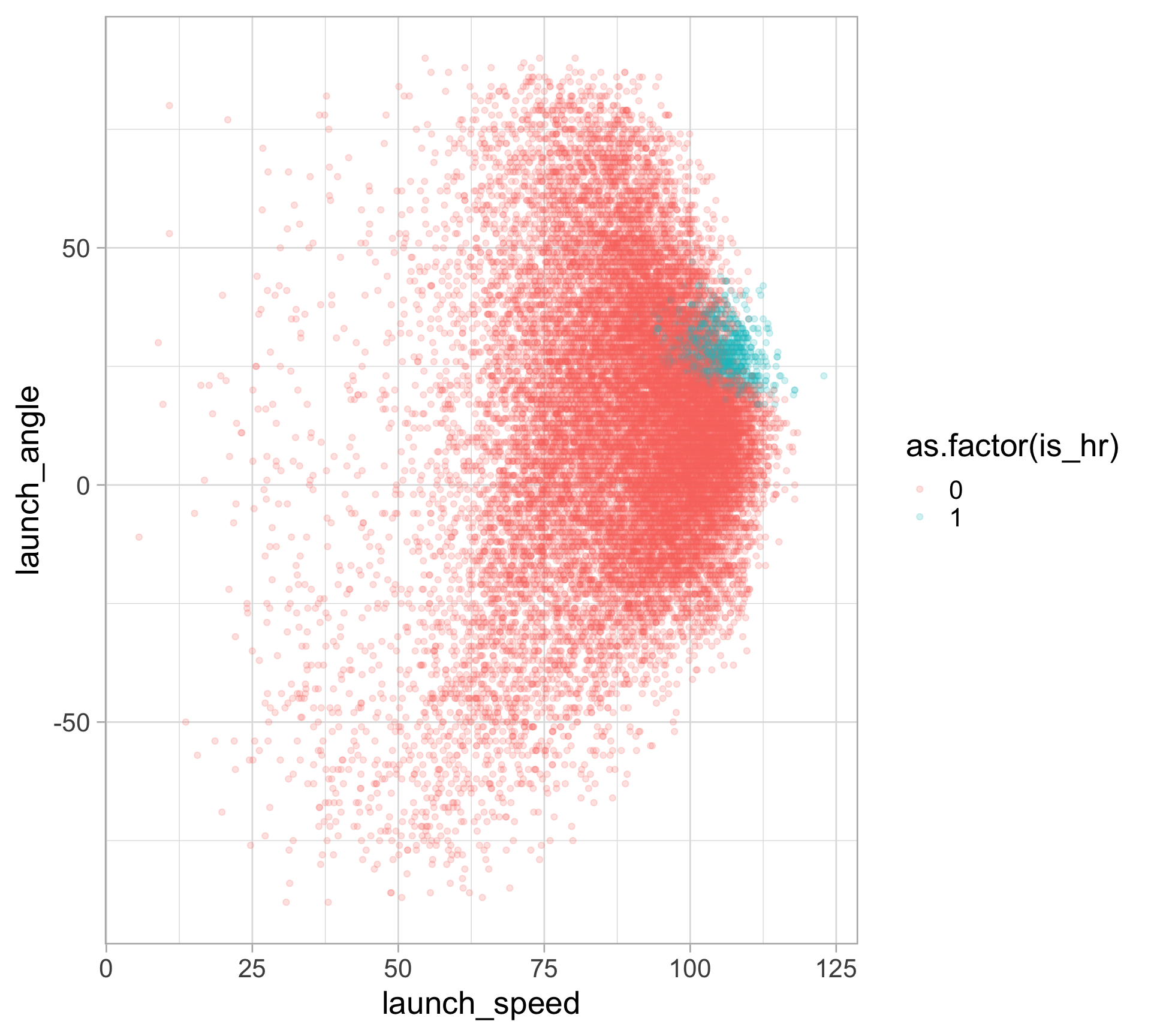
Predicting HRs with launch angle and exit velocity
There is a sweet spot of launch_angle (mid-way ish) and launch_speed (relatively high) where almost all HRs occur
batted_balls |>
group_by(
launch_angle_bucket = round(launch_angle * 2, -1) / 2,
launch_speed_bucket = round(launch_speed * 2, -1) / 2
) |>
summarize(hr = sum(is_hr == 1),
n = n()) |>
ungroup() |>
mutate(pct_hr = hr / n) |>
ggplot(aes(x = launch_speed_bucket,
y = launch_angle_bucket,
fill = pct_hr)) +
geom_tile() +
scale_fill_gradient2(labels = scales::percent_format(),
low = "blue",
high = "red",
midpoint = 0.2)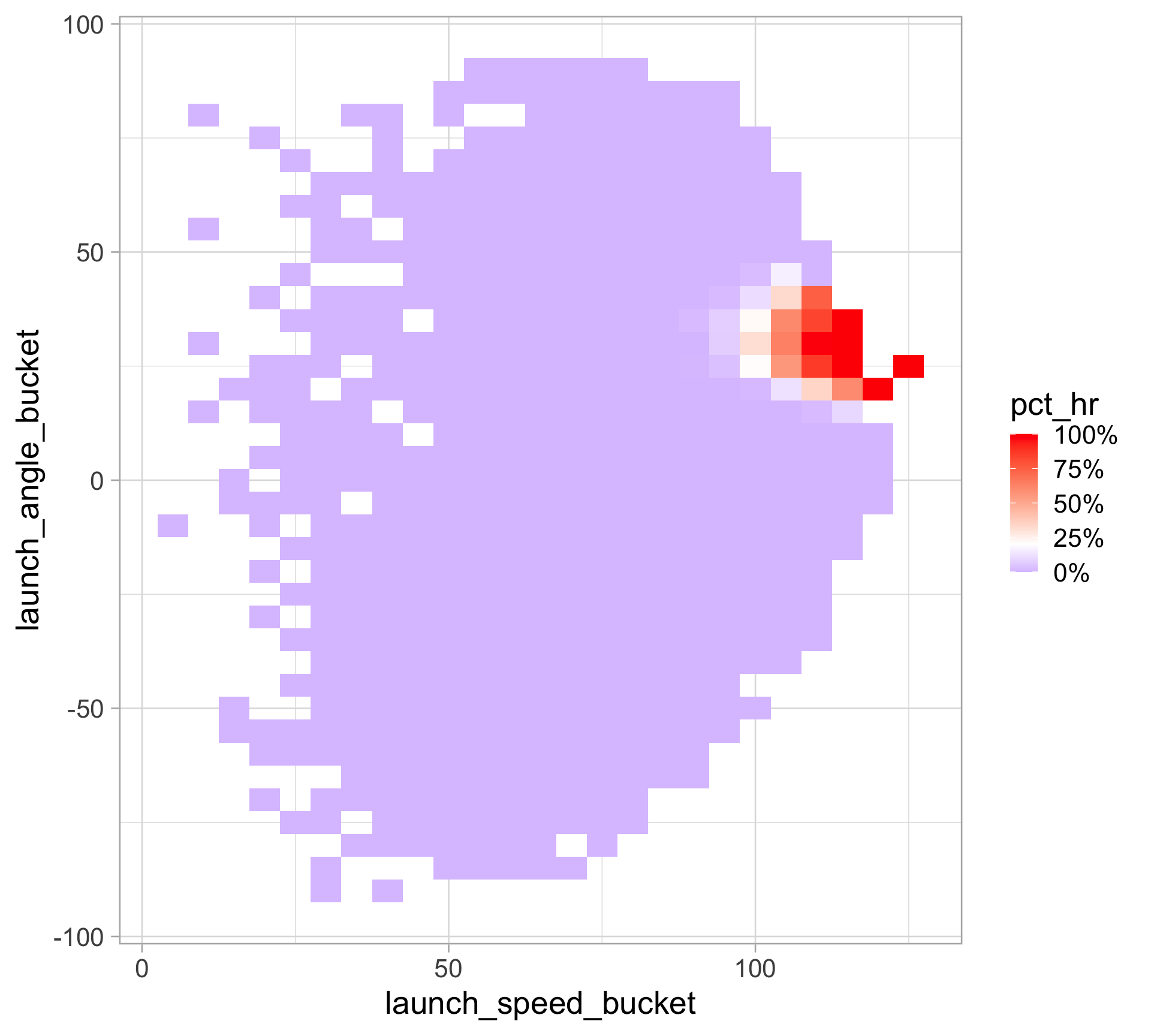
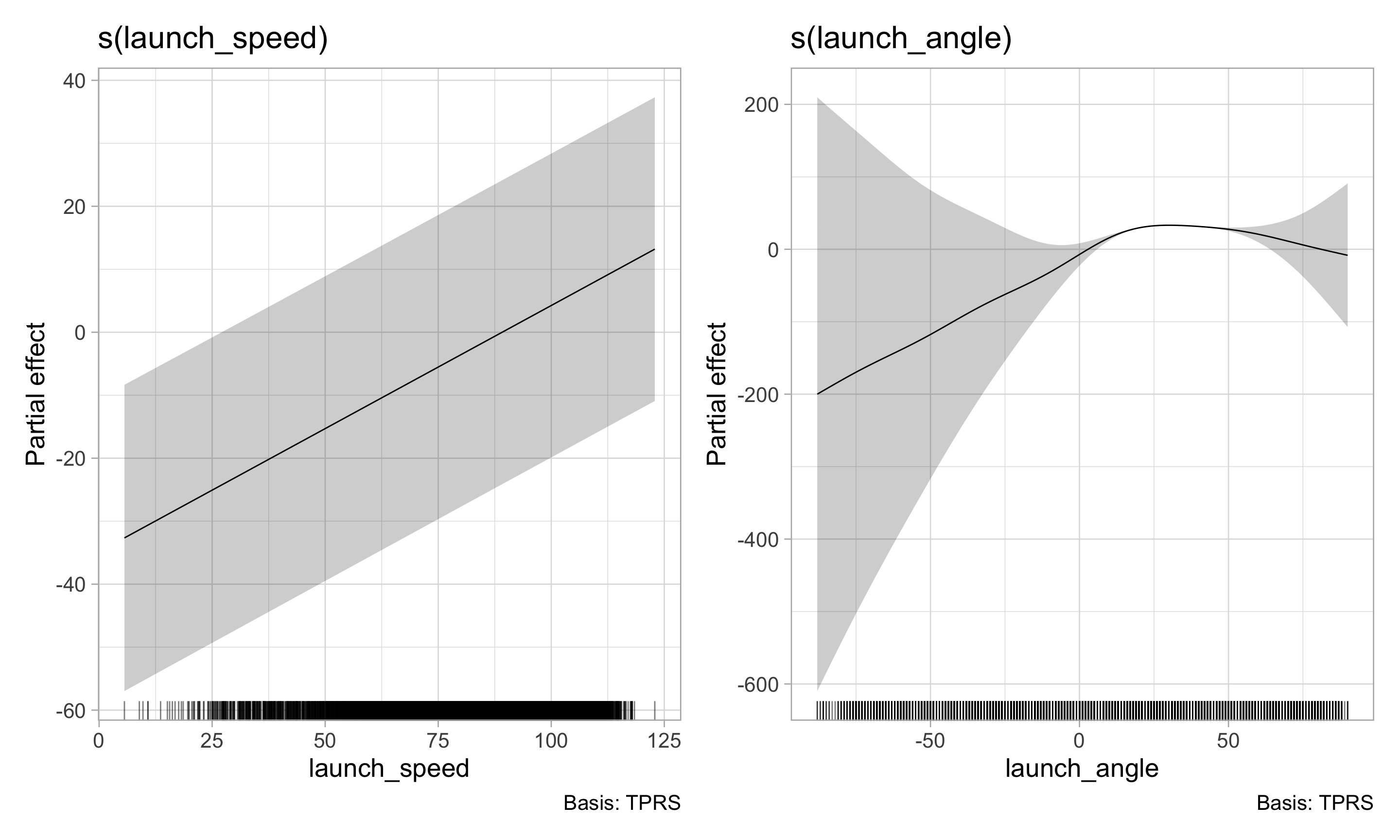
Visualize partial response functions
Display the partial effect of each term in the model and how they add up to the overall prediction
library(gratia)
draw(hr_gam)