Rows: 3,504
Columns: 7
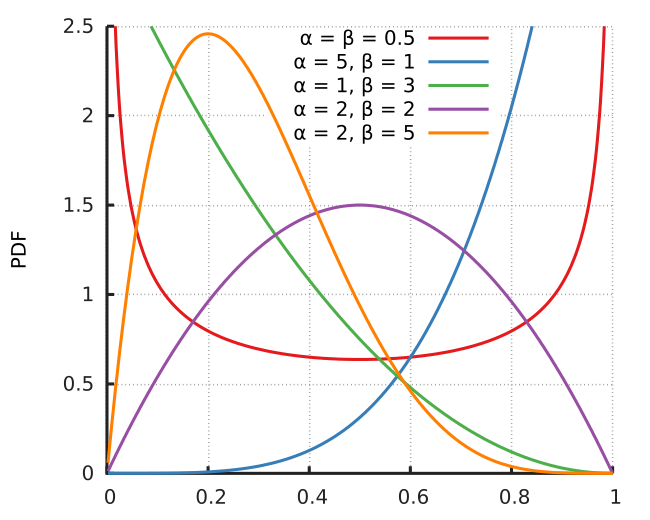
$ n_goals <dbl> 0, 2, 0, 0, 4, 1, 5, 2, 1, 1, 1, 0, 2, 5, 2, 0, 3, 1, 3, 0, 0…
$ xG <dbl> 0.3, 0.8, 2.7, 0.5, 4.0, 1.3, 3.3, 2.2, 1.4, 2.2, 0.6, 1.9, 1…
$ off_team <chr> "Burnley", "Arsenal", "Everton", "Sheffield Utd", "Brighton",…
$ def_team <chr> "Manchester City", "Nott'ham Forest", "Fulham", "Crystal Pala…
$ league <chr> "ENG", "ENG", "ENG", "ENG", "ENG", "ENG", "ENG", "ENG", "ENG"…
$ match_id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ is_home <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…